Управление уязвимостями: как правильно настроить triage и патч-менеджмент
 апр, 18 2026
апр, 18 2026
Представьте: ваш сканер безопасности выдал отчет на 500 страниц, где тысячи уязвимостей отмечены как «критические». Что делать первым? Бежать обновлять все сервера подряд, рискуя обрушить бизнес-процессы, или игнорировать отчет, надеясь на файрвол? В реальности большинство компаний тонут в этом потоке данных, потому что пытаются «лечить всё», вместо того чтобы управлять рисками. Управление уязвимостями - это не просто установка обновлений, а цикличный процесс, где главный вопрос не «что сломано?», а «что из этого реально может нас убить прямо сейчас?».
Главное об управлении уязвимостями
- Это бесконечный цикл: поиск → оценка → приоритизация → устранение → проверка.
- Triage (триаж) помогает отсеять шум и сфокусироваться на реальных угрозах.
- Патч-менеджмент - это способ доставки исправлений без остановки бизнеса.
- Если патча нет, используются компенсирующие меры (например, настройка WAF).
- Успех зависит от слаженности работы команд ИБ и системных администраторов.
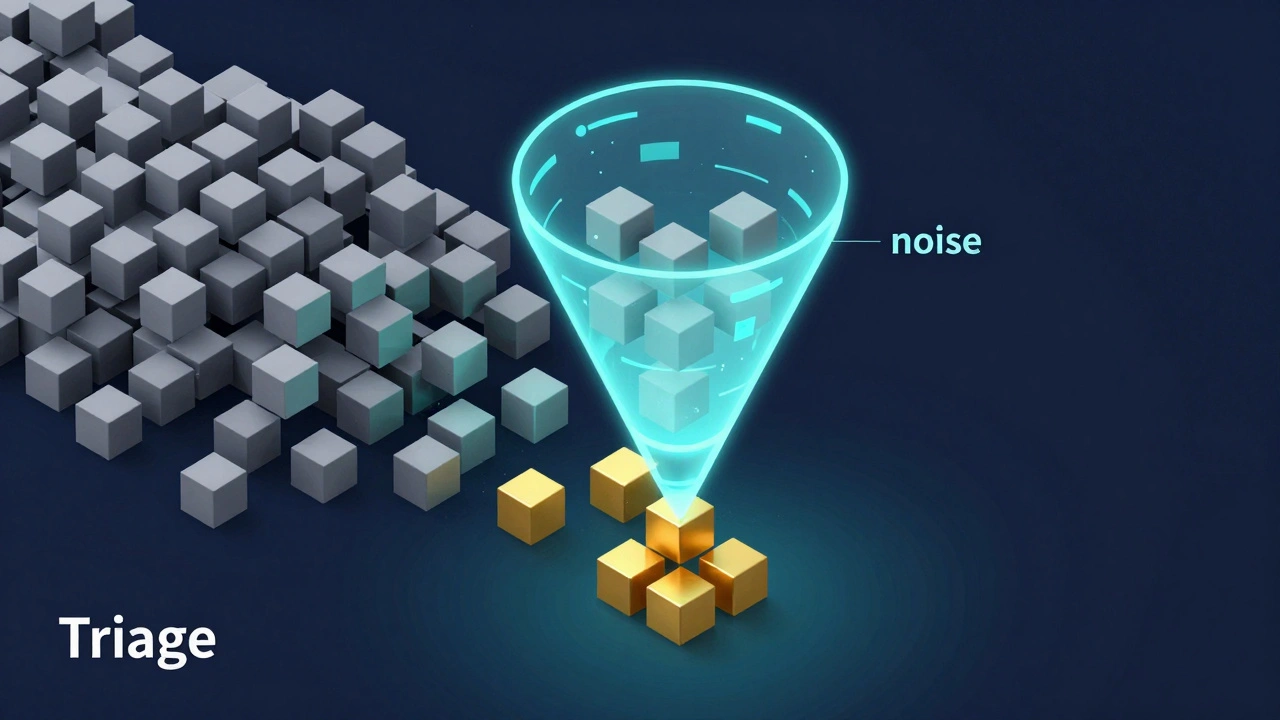
Что такое Triage и зачем он нужен
В медицине триаж - это сортировка раненых, чтобы спасти тех, кому помощь нужна в первую очередь. В IT всё работает так же. Triage - это этап первичного анализа уязвимости сразу после её обнаружения. Его цель - подтвердить, что проблема существует, и понять, насколько она опасна именно в вашем окружении .
Почему нельзя просто верить сканеру? Представьте, что система нашла критическую дыру в сервисе, который у вас выключен или находится в изолированном сегменте сети без доступа извне. Для сканера это «Critical», но для вашего бизнеса риск равен нулю. В процессе триажа специалисты проверяют контекст: есть ли доступ к этому порту? Работает ли функция, в которой найдена ошибка? Какие данные хранятся на этом сервере?
Правильный триаж превращает список из 1000 «критических» проблем в список из 10 действительно опасных. Это спасает админов от выгорания, а бизнес - от ненужных простоев.
Как работает процесс приоритизации рисков
Когда шум отсеян, начинается самая сложная часть - определение очереди. Ошибка многих компаний в том, что они смотрят только на CVSS (общий счет уязвимости). Но CVSS не знает, что ваш сервер с базой клиентов важнее, чем тестовый стенд с документацией.
Приоритизация должна строиться на пересечении трех факторов:
- Техническая тяжесть: Насколько легко эксплуатировать дыру? Нужны ли для этого права администратора или достаточно ссылки в браузере?
- Ценность актива: Что пострадает? Если это контроллер домена Active Directory, приоритет максимальный. Если старый принтер в бухгалтерии - можно подождать.
- Реальная угроза: Появился ли в сети рабочий эксплойт? Если хакеры уже вовсю используют эту уязвимость для атак на другие компании, время на исправление сокращается с недель до часов.
В России при организации этого процесса часто опираются на методические рекомендации ФСТЭК, которые подчеркивают необходимость создания актуального реестра активов. Нельзя защищать то, о чем вы даже не знаете.
Патч-менеджмент: искусство обновлять без боли
Патч-менеджмент - это системный процесс обновления ПО для устранения уязвимостей и ошибок . Кажется, что нужно просто нажать кнопку «Обновить», но в корпоративной среде один неудачный патч может «положить» всю ERP-систему или банковский шлюз.
Чтобы этого не случилось, внедряют поэтапное развертывание. Сначала обновление ставится на тестовый сервер (Staging), где проверяется, не отвалились ли критические функции. Затем - на небольшую группу рабочих станций или второстепенных серверов. И только после этого патч катится на весь продакшн.
Для критических систем часто устанавливают жесткие SLA (соглашения об уровне услуг). Например: «Критическая уязвимость с публичным эксплойтом должна быть закрыта в течение 48 часов». Это заставляет команды ИБ и IT заранее договариваться о «окнах обслуживания», чтобы обновление не стало сюрпризом в разгар отчетного периода.
| Критерий | Обновление (Патч) | Компенсирующая мера |
|---|---|---|
| Эффективность | Полное устранение причины | Снижение вероятности атаки |
| Скорость внедрения | Средняя (нужно тестирование) | Высокая (например, правило в WAF) |
| Влияние на стабильность | Может вызвать сбои в ПО | Минимальное |
| Срок действия | Постоянное решение | Временное (до выхода патча) |
Что делать, если патча нет или его нельзя поставить
Бывают ситуации, когда вендор забросил продукт (End of Life) или обновление ломает совместимость с другим важным софтом. В таком случае в игру вступают компенсирующие меры. Это «костыли» высокого уровня, которые делают эксплуатацию дыры почти невозможной.
Примеры таких мер:
- Сетевая изоляция: Закрыть доступ к уязвимому сервису для всех, кроме двух доверенных IP-адресов.
- Виртуальный патчинг: Настройка Web Application Firewall (WAF) так, чтобы он блокировал специфические запросы, использующие данную уязвимость.
- Ограничение прав: Запуск приложения от пользователя с минимальными привилегиями, чтобы даже при взломе хакер не смог выйти за пределы одной папки.
- Отключение функций: Если дыра в функции «экспорт в PDF», а она нужна раз в год - просто выключите её.
Важно помнить: компенсирующие меры требуют постоянного контроля. Если вы изменили настройки сети, чтобы закрыть дыру, нужно регулярно проверять, не открыл ли кто-то эти порты обратно «для удобства».
Интеграция в общие процессы компании
Управление уязвимостями не живет в вакууме. Если ИБ-специалист просто кидает в почту админу список из 100 серверов, которые нужно обновить, он получит в ответ раздражение. Процесс должен быть вшит в Change Management (управление изменениями).
Идеальный сценарий выглядит так: сканер находит уязвимость → система автоматически создает тикет в Jira/ServiceNow → специалист по триажу подтверждает риск и назначает приоритет → тикет уходит в бэклог системного администратора → после тестирования патча в тикете ставится отметка о выполнении → сканер делает повторную проверку и закрывает задачу.
Такой подход убирает человеческий фактор и позволяет руководству видеть реальную картину: сколько дыр закрыто, сколько «висит» и какой общий риск инфраструктуры на текущий момент.

Будущее: от реактивности к прогнозированию
Сегодня индустрия уходит от модели «нашли - починили» к предиктивному анализу. Компании начинают использовать данные о том, какие типы ошибок чаще всего встречаются в их коде или в софте конкретных вендоров. Это позволяет закладывать бюджет на замену устаревших систем еще до того, как в них найдут критическую уязвимость.
Также растет роль автоматизации. Современные системы умеют сами определять, какой патч совместим с текущей версией ОС, и предлагать оптимальный график обновления. Но даже при полной автоматизации финальное решение о «заливке» патча на критический сервер всё равно остается за человеком, который понимает цену минуты простоя бизнеса.
Что делать, если патч вызывает сбой в работе приложения?
В первую очередь нужно откатить обновление до стабильной версии. После этого следует зафиксировать ошибку, связаться с вендором или искать компенсирующие меры (например, ограничить доступ к уязвимой функции через файрвол), пока не выйдет исправленная версия патча.
Как часто нужно запускать сканирование на уязвимости?
Для критических сегментов сети сканирование должно быть непрерывным или ежедневным. Для общего парка устройств достаточно еженедельных проверок. Также рекомендуется запускать сканирование внепланово сразу после выхода критических обновлений от Microsoft, Linux или других основных вендоров.
Чем CVSS отличается от реального риска?
CVSS - это теоретическая оценка сложности и тяжести уязвимости «в вакууме». Реальный риск учитывает контекст: где находится сервер, кто имеет к нему доступ, какие данные на нем хранятся и есть ли активные атаки в сети. Уязвимость с CVSS 9.0 на изолированном тестовом сервере имеет гораздо меньший риск, чем уязвимость с CVSS 5.0 на основном веб-сервере компании.
Все ли уязвимости нужно закрывать немедленно?
Нет. Попытка закрыть всё сразу приведет к коллапсу ИТ-инфраструктуры. Используйте процесс триажа и приоритизации. Сначала закрываются «критические» дыры с доступными эксплойтами на важных активах, затем - всё остальное в порядке убывания риска.
Можно ли полностью автоматизировать патч-менеджмент?
Автоматизировать можно установку обновлений на рабочие станции пользователей. Однако для серверной инфраструктуры и критических приложений автоматический апдейт опасен. Здесь всегда должен быть этап ручного тестирования и одобрения специалистом.
Следующие шаги по настройке процесса
Если вы только начинаете выстраивать систему управления уязвимостями, не пытайтесь внедрить всё сразу. Начните с малого:
- Инвентаризация: Составьте список всех серверов и ПО. Вы не сможете обновить то, чего не видите.
- Выбор инструмента: Установите сканер уязвимостей и настройте базовые правила поиска.
- Регламент триажа: Договоритесь с ИТ-отделом, кто именно будет подтверждать уязвимости и в какие сроки.
- Тестовый полигон: Создайте среду, где можно безопасно проверять патчи перед установкой на «прод».
- Мониторинг: Настройте отчеты, чтобы видеть, как меняется количество открытых дыр от месяца к месяцу.