Платформенный инженер: кто это, зачем нужны IDP и как устроена роль в 2026 году
 мая, 20 2026
мая, 20 2026
Представьте ситуацию: вы разработчик, вам нужно запустить новый микросервис. Раньше это означало писать заявки в Service Desk, ждать неделю, пока DevOps настроит окружение, а потом еще неделю настраивать CI/CD пайплайн под конкретные нужды проекта. В 2026 году этот процесс выглядит иначе. Вы заходите во внутренний портал, выбираете шаблон «Spring Boot сервис», нажимаете кнопку, и через 15 минут у вас есть рабочий кластер с мониторингом, логированием и доступом к базе данных.
Тот, кто создал эту возможность - не волшебник и не просто системный администратор. Это платформенный инженер (Platform Engineer). Его задача - спроектировать и поддерживать внутреннюю платформу для разработчиков (Internal Developer Platform, IDP), которая превращает сложную инфраструктуру в простой самообслуживающийся продукт.
Роль платформенного инженера стала одной из самых востребованных в IT-индустрии последних лет. Если раньше DevOps-инженеры пытались быть «универсальными солдатами», то теперь фокус смещается на создание специализированных продуктов для команд разработки. Давайте разберемся, чем именно занимается эта профессия, какие технологии использует и почему компании готовы платить за таких специалистов больше, чем за классических DevOps-инженеров.
Что такое Platform Engineering и откуда взялась роль?
Platform Engineering - это дисциплина проектирования и создания внутренних платформ разработки (IDP). По сути, это слой между командами разработки и низкоуровневой инфраструктурой. Главная цель - снизить когнитивную нагрузку на разработчиков, чтобы они могли сосредоточиться на бизнес-логике, а не на настройке Kubernetes или написании Terraform-скриптов.
Исторически эта концепция оформилась после выхода книги «Team Topologies» Мэтью Скэлтена и Мануэля Пайса в 2019 году. Авторы предложили модель, где вместо того, чтобы каждый разработчик занимался операциями («все делают всё»), создается отдельная платформенная команда, которая предоставляет услуги по модели внутреннего продуктового провайдера.
В 2022 году аналитики Gartner спрогнозировали, что к 2026 году 80% организаций по созданию ПО сформируют такие команды. Прогноз сбылся: сегодня крупные российские и международные компании (Яндекс, VK, Tinkoff, Spotify, Zalando) активно используют IDP. Разница между старым подходом и новым проста:
- DevOps (старая модель): Инженер помогает команде вручную настроить инфраструктуру. Это масштабируется плохо: чем больше команд, тем больше требуется инженеров.
- Platform Engineering (новая модель): Инженер создает автоматизированный инструмент (портал), который позволяет командам самим создавать инфраструктуру по стандартам. Это масштабируется хорошо: один инженер может обслуживать десятки команд.
Архитектура IDP: из чего состоит внутренняя платформа?
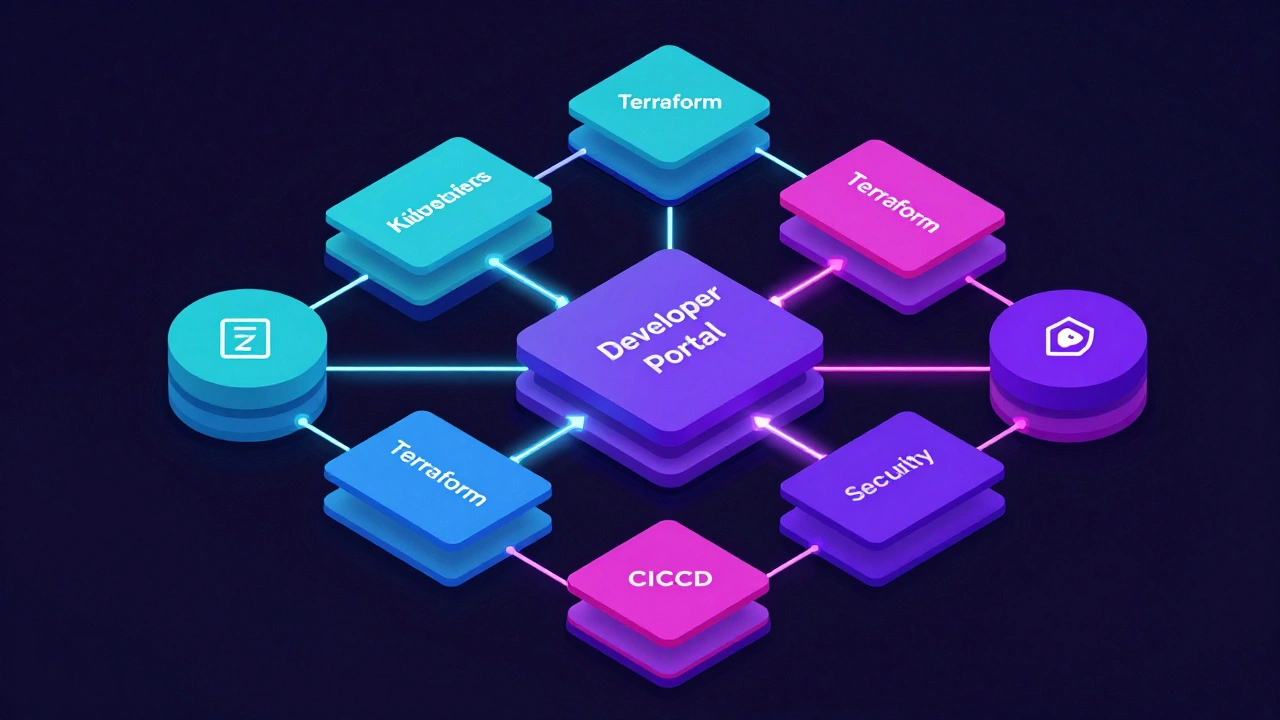
IDP - это не один инструмент, а экосистема. Типичная архитектура включает несколько ключевых компонентов, которые работают вместе:
| Компонент | Назначение | Примеры технологий |
|---|---|---|
| Developer Portal | Единая точка входа (веб-интерфейс), где разработчики видят свои сервисы, запускают деплой и читают документацию. | Backstage (Spotify/CNCF), Port, Cortex |
| Service Catalog | Реестр всех сервисов, API, владельцев и зависимостей. Решает проблему «кто этим владеет?». | Модули Backstage, custom решения |
| Golden Paths | Готовые шаблоны проектов с best practices по безопасности, логированию и мониторингу. | Helm charts, Cookiecutter, Yeoman |
| Infrastructure Orchestration | Слой, который принимает запросы с портала и управляет реальной инфраструктурой. | Kubernetes, Terraform, Crossplane |
| GitOps Layer | Автоматическая синхронизация состояния инфраструктуры с Git-репозиторием. | Argo CD, FluxCD |
| Observability | Агрегация метрик, логов и трассировок в удобных дашбордах. | Prometheus, Grafana, Loki, Jaeger |
| Security & Compliance | Управление секретами, сканирование уязвимостей, политики доступа. | Vault, OPA, Trivy |
Ключевое слово здесь - self-service. Разработчик должен иметь возможность создать тестовое окружение, получить доступ к базе данных или развернуть новый сервис без обращения к другим командам. Платформенный инженер проектирует эти процессы так, чтобы они были безопасными, но максимально простыми.
Чем платформенный инженер отличается от DevOps и SRE?
Эти термины часто путают, но у каждой роли своя зона ответственности. Понимание различий критически важно при построении команды.
DevOps - это скорее культура и набор практик взаимодействия разработки и эксплуатации. Классический DevOps-инженер часто работает напрямую с конкретной продуктовой командой, помогая им решать оперативные проблемы.
SRE (Site Reliability Engineer) фокусируется на надежности, SLA/SLO и инцидентах. Их задача - убедиться, что система не падает, и автоматизировать рутинные операции поддержки.
Platform Engineer же выступает как внутренний продавец продукта. Он не решает конкретные задачи одной команды, а создает инструменты, которые решают общие задачи для всех. Например:
- SRE пишет скрипт для перезагрузки упавшего сервиса.
- DevOps помогает команде настроить Jenkins.
- Platform Engineer создает универсальный пайплайн сборки в GitLab/GitHub Actions, который автоматически подключает мониторинг и безопасность, и делает его доступным через портал для любой новой команды.
По данным отчетов Humanitec и Enabling.team, в зрелых организациях платформенные команды работают как внутренние провайдеры услуг, измеряя свой успех через удовлетворенность разработчиков (NPS) и скорость доставки (Lead Time).
Навыки и стек технологий платформенного инженера
Стать платформенным инженером сложнее, чем стать обычным DevOps-специалистом, потому что требуются навыки не только в инфраструктуре, но и в разработке программного обеспечения, и в продуктовом мышлении.
Типовой стек компетенций включает:
- Программирование: Уверенное знание хотя бы одного языка общего назначения. Чаще всего это Go (для инструментов CLI и операторов Kubernetes), Python (для автоматизации и скриптов) или TypeScript/Node.js (для фронтенда порталов типа Backstage).
- Контейнеризация и оркестрация: Глубокое понимание Kubernetes (версии 1.20+). Нужно уметь писать Helm-чарты, понимать Custom Resource Definitions (CRD) и Operators.
- Infrastructure as Code (IaC): Опыт работы с Terraform (0.12+) или аналогами (Pulumi, Crossplane). Важно уметь модулировать код и управлять состоянием.
- CI/CD и GitOps: Понимание принципов непрерывной интеграции. Знание инструментов вроде GitHub Actions, GitLab CI, Jenkins, а также Argo CD или FluxCD для GitOps-подходов.
- Observability: Навыки настройки стека наблюдаемости: Prometheus для метрик, Grafana для визуализации, Loki/ElasticSearch для логов, OpenTelemetry/Jaeger для трассировок.
- Безопасность: Управление секретами через HashiCorp Vault или cloud-native решения, внедрение Policy-as-Code через Open Policy Agent (OPA).
Помимо технических навыков, критически важным является продуктовое мышление. Платформенный инженер должен уметь общаться с разработчиками, собирать обратную связь, приоритизировать бэклог платформы и измерять её эффективность. Без этого платформа рискует стать «вторым монолитом», которым никто не пользуется.
Как внедряется IDP: шаги и сроки
Создание внутренней платформы - это не разовый проект, а долгосрочная стратегия. Ошибкой многих компаний было попытка построить идеальную платформу за год без участия целевых пользователей. Результатом часто становилось низкое принятие (менее 20-30% команд).
Рекомендуемый путь внедрения включает следующие этапы:
- Аудит болей: Опросите разработчиков. Что их тормозит? Долго ли создаются окружения? Сложно ли разобраться в мониторинге? Измерьте текущие метрики: Time to First Deploy, Lead Time for Changes.
- Определение MVP (Minimum Viable Platform): Начните с узкого сценария. Например, реализуйте один «Golden Path» для типичного веб-сервиса на Java или Go. Не пытайтесь охватить все языки и типы приложений сразу.
- Разработка ядра: Настройте базовую инфраструктуру (Kubernetes, Terraform), интегрируйте CI/CD и создайте простой портал (можно начать с документации + скриптов, затем перейти на Backstage).
- Онбординг первых команд: Привлеките 2-3 добровольческие команды. Работайте с ними тесно, собирайте фидбек, исправляйте недочеты.
- Масштабирование: Постепенно добавляйте новые шаблоны, улучшайте UX портала, расширяйте функционал безопасности и мониторинга.
По опыту крупных компаний, запуск MVP занимает от 3 до 9 месяцев. До состояния «зрелой» платформы, когда 70-80% новых сервисов создаются через неё, проходит 12-24 месяца. Ключевой показатель успеха - не количество функций в портале, а процент команд, которые реально используют платформу (Adoption Rate).

Плюсы и риски подхода
Внедрение IDP дает значительные бизнес-преимущества:
- Ускорение Time-to-Market: Время создания нового сервиса сокращается с недель до часов.
- Снижение затрат: Консолидация инструментов (например, отказ от множества разных CI-систем в пользу одной стандартизированной) экономит лицензии и ресурсы.
- Стабильность: Единые стандарты безопасности и мониторинга снижают количество инцидентов.
- Масштабируемость: Компания может расти линейно по количеству продуктовых команд, не увеличивая штат инфраструктурных инженеров пропорционально.
Однако есть и риски:
- «Бутылочное горлышко»: Если платформа слишком медленная или ограничивает возможности команд, разработчики начнут обходить её, создавая «теневую» инфраструктуру.
- Высокая стоимость поддержки: Поддержание сложной экосистемы требует квалифицированных кадров и постоянного инвестирования.
- Отрыв от реальности: Платформа должна развиваться исходя из потребностей пользователей, а не фантазий архитекторов.
Эксперты рекомендуют применять принцип «Platform as a Product»: относиться к платформе как к коммерческому продукту, где разработчики - ваши клиенты. Регулярно измеряйте NPS (Net Promoter Score) и готовность рекомендовать платформу коллегам.
Перспективы профессии в России и мире
К 2026 году роль платформенного инженера перестала быть экспериментальной. В России спрос на таких специалистов растет в финансовом секторе, телекоме и e-commerce. Появились профильные курсы (например, от Otus), консалтинговые предложения и публикации крупных игроков (Яндекс Cloud, VK Cloud).
Зарплатные ожидания платформенных инженеров обычно выше, чем у классических DevOps, из-за более широкого набора навыков (разработка + инфраструктура + продукт). Соотношение в зрелых командах составляет примерно 1 платформенный инженер на 20-30 продуктовых разработчиков.
Будущее направления связано с углублением автоматизации (AI-assisted coding в инфраструктуре), усилением безопасности (Zero Trust архитектуры) и фокусом на Developer Experience. Если вы хотите развиваться в инфраструктуре, переход от DevOps к Platform Engineering - это логичный и перспективный шаг.
Нужно ли знать программирование, чтобы стать платформенным инженером?
Да, обязательно. В отличие от классического SysAdmin, платформенный инженер пишет код. Вам понадобится уверенное знание Go, Python или TypeScript для создания инструментов, плагинов для порталов (например, Backstage) и автоматизации процессов. Без навыков разработки сложно создавать гибкие и поддерживаемые решения.
Что такое Golden Paths в контексте IDP?
Golden Paths - это заранее подготовленные шаблоны проектов и пайплайнов, которые включают лучшие практики безопасности, логирования и мониторинга. Разработчик выбирает шаблон (например, «Spring Boot API»), и платформа автоматически создает всю необходимую инфраструктуру. Это ускоряет старт новых проектов и гарантирует единообразие.
Стоит ли изучать Backstage, если компания не использует его?
Backstage является де-факто стандартом для open-source порталов разработчиков благодаря поддержке CNCF. Даже если ваша компания использует другое решение (Port, Cortex или самописное), принципы работы Backstage (Service Catalog, Software Templates) широко применимы. Знание экосистемы Backstage повышает вашу ценность как специалиста.
Как измерить эффективность работы платформенной команды?
Используйте метрики DORA (Lead Time for Changes, Deployment Frequency, Change Failure Rate, Mean Time to Recovery) в сочетании с метриками удовлетворенности разработчиков (NPS, CSAT). Также важно отслеживать Adoption Rate - процент команд, которые реально используют платформу для создания новых сервисов.
Какова разница между Platform Engineer и SRE?
SRE фокусируется на надежности конкретных сервисов, инцидентах и SLA. Platform Engineer создает инструменты и платформы, которые позволяют многим командам самостоятельно обеспечивать надежность и операционную эффективность. SRE работает «в глубину» с сервисами, Platform Engineer - «в ширину» с инструментами.