MLOps инженер в IT: как строить инфраструктуру и доставлять ML-модели в продакшн
 мар, 10 2026
мар, 10 2026
Если вы когда-нибудь видели, как модель машинного обучения работает идеально в тестовой среде, а в продакшне начинает выдавать ошибки или вообще перестаёт работать - вы понимаете, почему нужен MLOps инженер. Это не просто ещё один Data Scientist, который умеет писать код. Это человек, который строит систему, чтобы ML-модели не ломались, не теряли точность и не останавливали бизнес из-за технических сбоев.
Что делает MLOps инженер?
MLOps инженер - это мост между командой, которая создаёт модели, и командой, которая поддерживает серверы и инфраструктуру. ML-специалисты придумывают алгоритмы, тренируют модели, проверяют метрики. Но когда модель готова - кто её запустит на серверах? Кто следит, чтобы она не упала после обновления данных? Кто обеспечит, чтобы новая версия модели не сломала всё, что работает в продакшне?
Вот тут и вступает в дело MLOps. Его задача - сделать процесс доставки модели таким же предсказуемым, как деплой веб-приложения. Вместо того чтобы каждый раз вручную копировать файлы, запускать скрипты и ждать, пока кто-то из команды проверит, что всё работает - всё должно автоматизироваться. И именно MLOps инженер создаёт эту автоматизацию.
Как устроена инфраструктура MLOps
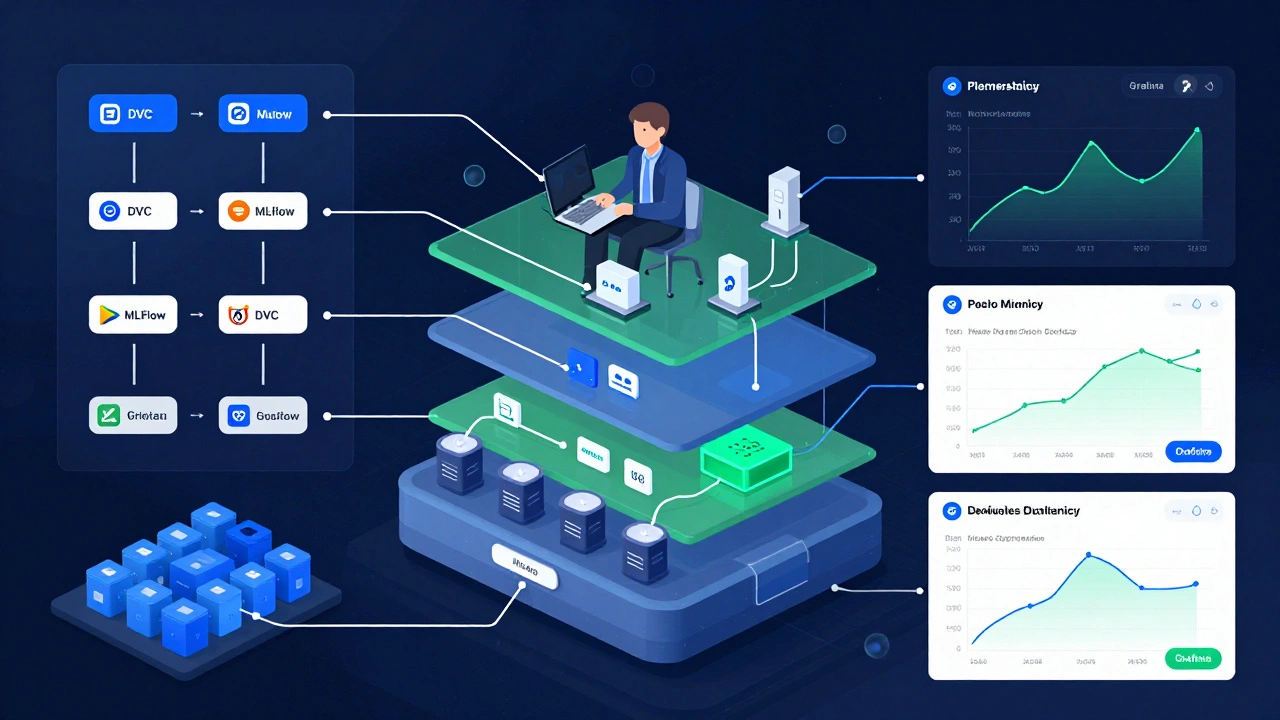
Инфраструктура для ML-моделей - это не просто облачные серверы. Это целая система, состоящая из нескольких слоёв:
- Слой данных - где хранятся сырые данные, фичи, версии датасетов. Здесь используются решения вроде DVC (Data Version Control) и MLflow (система для управления экспериментами и версионирования моделей). Без них вы не сможете отследить, какая именно версия данных привела к улучшению точности модели.
- Слой автоматизации - это CI/CD-пайплайны, но не для обычного кода, а для ML. Тут не просто запускается тест - тестируется точность модели, проверяется сдвиг данных (data drift), сравнивается производительность новой и старой версии. Инструменты: Apache Airflow (оркестратор задач), Kubeflow (платформа для ML на Kubernetes).
- Слой деплоя - модели должны работать в реальном времени. Для этого их упаковывают в контейнеры с помощью Docker (технология контейнеризации) и разворачивают на Kubernetes (системе управления контейнерами). Это позволяет масштабировать сервисы под нагрузку и автоматически перезапускать их при сбоях.
- Слой мониторинга - модель не работает один раз и всё. Она должна постоянно проверяться: не изменились ли входные данные? Не упала ли точность? Не появились ли смещения в распределении фич? Для этого используются инструменты вроде Prometheus (мониторинг метрик) и Grafana (визуализация данных).
- Слой безопасности - секреты, ключи доступа, токены API - всё это хранится в Key Vault (системах безопасного хранения секретов). Никто не должен иметь доступ к данным или API без явного разрешения.
Всё это вместе - и есть MLOps-инфраструктура. Она не появляется за один день. Её проектируют, тестируют, дорабатывают - как обычное ПО.
Жизненный цикл модели под MLOps
Обычный ML-инженер думает: «Я обучил модель - всё, готово». MLOps инженер знает: это только начало. Жизненный цикл модели под MLOps выглядит так:
- Подготовка данных - очистка, фильтрация, генерация фичей. Здесь же фиксируется версия датасета.
- Обучение и эксперименты - запускается несколько версий модели, сравниваются метрики. Всё фиксируется в MLflow.
- Тестирование - не просто точность, а ещё: стабильность, скорость предсказания, устойчивость к шуму. Тестируется не только код, но и данные.
- Деплой - модель упаковывается в Docker, разворачивается на Kubernetes, запускается как API-сервис.
- Мониторинг - система следит за точностью, задержками, количеством ошибок. Если точность падает на 5% - автоматически запускается тренировка новой версии.
- Обновление - если новая модель прошла проверки, она заменяет старую. Без ручного вмешательства.
Представьте, что ваша модель - это автомобиль. MLOps - это автосервис, который не только ремонтирует его, но и заранее меняет масло, проверяет шины и обновляет ПО, пока вы ещё не почувствовали, что что-то пошло не так.

Инструменты, которые использует MLOps инженер
Вот список ключевых технологий, которые вы встретите в реальном MLOps-стеке:
| Инструмент | Функция | Почему важен |
|---|---|---|
| DVC | Версионирование данных и моделей | Без DVC вы не сможете откатиться к рабочей версии, если новая модель стала хуже. |
| MLflow | Управление экспериментами, регистрация моделей | Позволяет сравнивать сотни запусков и выбрать лучшую версию. |
| Apache Airflow | Оркестрация пайплайнов | Запускает подготовку данных, обучение, тестирование - в нужном порядке и по расписанию. |
| Kubeflow | Платформа для ML на Kubernetes | Объединяет все этапы: от обучения до деплоя - в единой среде. |
| Docker | Контейнеризация | Гарантирует, что модель будет работать одинаково на сервере и на локальной машине. |
| Kubernetes | Управление контейнерами | Автоматически масштабирует сервисы, перезапускает их при сбоях. |
| TensorFlow Serving | Сервис для предсказаний | Оптимизирован для высокой производительности при инференсе моделей TensorFlow. |
Это не всё - есть ещё Databricks (платформа для работы с большими данными и ML), Weights & Biases (инструмент для анализа экспериментов), Terraform (инфраструктура как код). Но даже эти семь - уже достаточно, чтобы начать строить систему.
Почему MLOps - это не просто «ещё одна роль»
Многие компании думают: «У нас есть Data Scientist - пусть он и деплоит модель». Но на практике это проваливается. Почему?
- ML-специалисты редко разбираются в Kubernetes, Docker, CI/CD-пайплайнах.
- Они не хотят заниматься инфраструктурой - им интересны алгоритмы, а не логи серверов.
- Когда модель ломается в продакшне - никто не знает, кто виноват: ML-инженер или DevOps?
MLOps инженер - это человек, который берёт на себя ответственность за всю цепочку. Он не пишет алгоритмы, но он создаёт систему, в которой алгоритмы работают без сбоев. Он не просто запускает модель - он гарантирует, что она будет работать месяцами, даже если данные меняются, нагрузка растёт, или кто-то случайно обновил базу данных.
В Новосибирске, как и в других крупных IT-центрах, компании, которые используют ML для прогнозирования спроса, оптимизации логистики, анализа клиентов - уже давно нанимают MLOps-инженеров. Это не тренд. Это необходимость.
Как стать MLOps инженером
Если вы уже работаете в IT и хотите перейти в эту роль - вот что нужно знать:
- Основы DevOps - понимание CI/CD, Docker, Kubernetes, Terraform.
- Опыт с ML - вы должны понимать, как работает обучение модели, что такое overfitting, data drift, A/B тестирование.
- Практика - создайте свой пайплайн. Возьмите открытый датасет (например, из Kaggle), обучите модель, упакуйте в Docker, разверните на Kubernetes, настройте мониторинг. Это ваш портфолио.
- Инструменты - начните с MLflow и DVC. Они проще, чем Kubeflow, и отлично подходят для старта.
Не нужно быть гением в программировании. Нужно быть системным мыслителем. MLOps - это про стабильность, про надёжность, про то, чтобы всё работало, даже когда никто не смотрит.
Пример из жизни: как MLOps спасает транспорт
В Сингапуре MLOps используется для управления трафиком. Модель предсказывает, где завтра будет пробка. Если модель обновляется вручную - это занимает недели. С MLOps - всё автоматически: как только новые данные о пробках поступают, система запускает переобучение, проверяет точность, если всё хорошо - заменяет модель в продакшне. Всё за 4 часа. Без участия человека.
Результат? На 15% меньше времени в пробках. И это не теория - это реальный кейс, который работает уже несколько лет.
В России такие системы тоже появляются - в логистике, в банках, в ритейле. Компании, которые не внедряют MLOps, рискуют остаться на заднем плане. Потому что модели, которые не обновляются, становятся бесполезными. А те, кто умеет их автоматически доставлять - получают конкурентное преимущество.
Чем MLOps инженер отличается от Data Scientist?
Data Scientist создаёт и тренирует модели, анализирует данные, ищет закономерности. MLOps инженер не создаёт модели - он обеспечивает, чтобы они работали в продакшне. Он отвечает за автоматизацию, деплой, мониторинг и масштабирование. Первый думает: «Как сделать модель точнее?» Второй - «Как сделать так, чтобы модель не сломалась, когда её запустят на 10 000 запросов в минуту?»
Нужно ли MLOps инженеру уметь писать код на Python?
Да, обязательно. Но не для создания сложных моделей - а для написания скриптов автоматизации, настройки пайплайнов, взаимодействия с API и отладки. Вы не должны быть экспертом в PyTorch, но должны уверенно писать код на Python, чтобы настроить Dockerfile, Airflow DAG или скрипт мониторинга.
Можно ли стать MLOps инженером без опыта в DevOps?
Можно, но это будет сложно. MLOps - это гибрид. Если вы знаете ML, но не знаете Docker или Kubernetes - вам придётся изучать это параллельно. Лучший путь: начните с DevOps-роли (например, как Junior DevOps), потом добавьте знания ML. Так вы поймёте, как инфраструктура влияет на модели, а не просто будете их запускать.
Какие компании в России нанимают MLOps инженеров?
Крупные компании, которые используют ML: Сбербанк, Тинькофф, Яндекс, ВТБ, Ozon, Wildberries, Касперский, а также логистические компании вроде СДЭК и Деливери. В Новосибирске, Казани, Екатеринбурге и других IT-центрах такие позиции появляются в стартапах и IT-подразделениях крупных предприятий - особенно там, где есть аналитика, прогнозирование спроса или оптимизация процессов.
Что делать, если у меня нет доступа к облаку для практики?
Начните с локальной машины. Установите Docker, создайте простой пайплайн: загрузите датасет, обучите линейную модель, упакуйте её в контейнер, запустите локально как API. Используйте MLflow для отслеживания экспериментов. Потом попробуйте развернуть всё на бесплатном Kubernetes от Google (GKE) или AWS (EKS) - у них есть бесплатные тарифы для обучения. Главное - сделать хотя бы один полный цикл: от данных до деплоя.