Как пережить продакшн-инцидент в IT и не выгореть: гид по выживанию для команды
 апр, 30 2026
апр, 30 2026
Когда в два часа ночи в Slack начинает разрываться чат, а графики мониторинга окрашиваются в кроваво-красный цвет, в крови каждого участника команды мгновенно подскакивает кортизол. Продакшн-инцидент - это не просто техническая проблема, которую нужно пофиксить. Это мощный стресс-тест для психики, где цена ошибки - не только деньги компании, но и выгорание в it, которое может выбить специалиста из колеи на месяцы. Чтобы после очередной «пожарной» смены не обнаружить себя в состоянии глубокой апатии, нужно перестать относиться к авариям как к стихийному бедствию и начать управлять ими как бизнес-процессом.
Первые минуты хаоса: как не дать панике захватить управление
Самое опасное в любой аварии - это ощущение неопределенности. Когда никто не понимает, кто главный и что делать, начинается паника, которая парализует даже самых опытных сеньоров. Чтобы этого избежать, нужно внедрить жесткий алгоритм сбора команды. Как только подтвержден критический сбой, все текущие задачи отправляются в корзину. Сейчас приоритет один - вернуть сервис в рабочее состояние.
Вместо бесконечного переписывания сообщений в чате, немедленно создавайте звонок. Живое общение сокращает время реакции в разы: вы слышите интонации, можете быстро перебить или уточнить деталь, не дожидаясь, пока собеседник допишет абзац текста. В этом звонке должны быть три стороны: саппорт (который видит боль пользователей), разработчик или DevOps-инженер (который знает, где «лежит» проблема) и руководитель, который берет на себя административную нагрузку.
Для структурирования общения используйте протокол SBAR (Situation, Background, Assessment, Recommendation). Это метод из медицины, который идеально ложится на IT: краткое описание ситуации, контекст (что предшествовало), оценка текущего состояния и конкретное предложение по решению. Это убирает лишний шум и заставляет мозг работать в режиме поиска решения, а не в режиме панического крика.
Распределение ролей: кто за что отвечает в «режиме пожара»
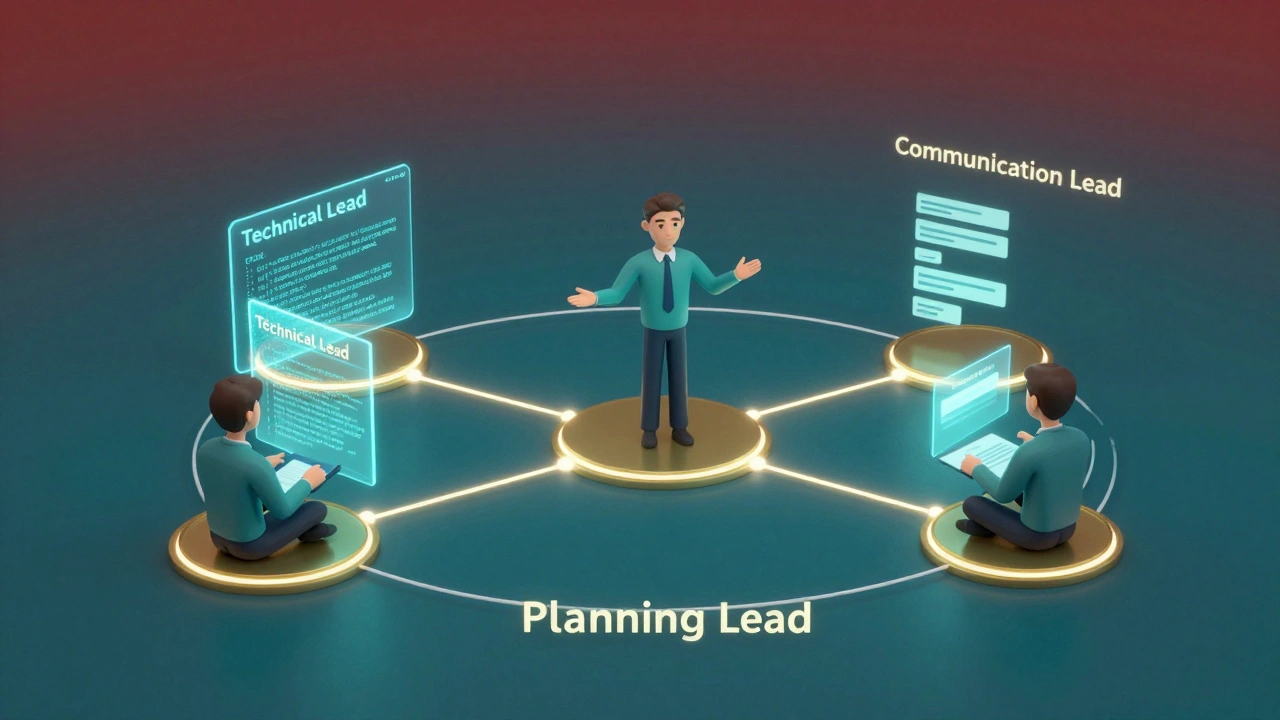
Когда все пытаются чинить всё одновременно, возникает эффект «слишком много поваров на одной кухне». Чтобы сохранить здоровье команды, нужно четко разделить зоны ответственности. Если инцидент крупный, введите роль Planning Lead. Это человек, который сам не пишет код в этот момент, но выступает в роли «диспетчера». Его задача - собирать данные из логов и мониторинга, вести хронологию событий и прогнозировать, где команда будет через 30-60 минут.
| Роль | Основная задача | Влияние на стресс |
|---|---|---|
| Planning Lead | Сбор данных, таймлайн, прогнозы | Снижает хаос, убирает неопределенность |
| Technical Lead / Fixer | Поиск и устранение причины сбоя | Фокусируется на задаче, не отвлекаясь на чаты |
| Communication Lead | Связь с пользователями и бизнесом | Защищает технарей от «почему всё еще не работает?» |
Зачем так усложнять? Потому что когда разработчик, который пытается восстановить базу данных, одновременно должен отвечать аккаунт-менеджеру о сроках, его когнитивная нагрузка зашкаливает. Ошибка в такой ситуации почти неизбежна. Разделение ролей - это лучший способ сохранить рассудок и скорость работы.
Психологическая гигиена во время и после аварии
Главное правило выживания: сохраняйте внешнее спокойствие. Это может звучать как банальный совет из учебника, но на деле это работает как эмоциональный якорь. Если лидер команды говорит спокойным, размеренным тоном, уровень тревоги у остальных падает. Паника заразна, но спокойствие тоже.
Помните, что безопасность людей важнее доступности сайта. Если инженер работает 12 часов подряд без перерыва на еду и сон, он становится опасен для системы. Введите правило принудительных перерывов. Даже 15 минут в полной тишине без экранов помогают мозгу перезагрузиться и увидеть решение, которое ускользало часами.
Когда всё наконец заработало, наступает самый опасный момент - эмоциональный откат. Именно здесь возникает риск выгорания. Нельзя просто сказать «фух, пронесло» и пойти спать. Необходим системный выход из стресса. Сначала составляется Incident Report (ИР). Это документ, который фиксирует, что произошло и как это было решено. Важно: ИР - это не поиск виноватых, а поиск дыр в процессе.
Если же авария случилась из-за личной ошибки сотрудника, вместо публичной порки используйте инструмент рефлексии. Человек должен в спокойной обстановке ответить себе на вопросы: «Почему я принял это решение?», «Какая установка в моей голове привела к ошибке?». Это превращает травмирующий опыт в профессиональный рост, а не в повод для депрессии.

Системная профилактика: как подготовить психику к будущим сбоям
Если вы ждете первого инцидента, чтобы начать настраивать процессы, вы уже проиграли. Подготовка должна быть частью культуры. Один из лучших методов - Tabletop Exercises (настольные учения). Это когда команда собирается в переговорке, и ведущий говорит: «Представьте, что у нас упал основной регион AWS, а бэкапы не восстанавливаются. Ваши действия?».
Такие обсуждения в режиме «песочницы» позволяют выявить пробелы в доступах или недопонимания в ролях без риска обрушить реальный бизнес. Когда человек однажды «прожил» сценарий аварии в теории, реальный сбой вызывает у него не панику, а ощущение знакомого алгоритма: «А, мы это обсуждали на учениях, сейчас делаем вот это».
Кроме технических упражнений, важна эмоциональная поддержка. Руководителю стоит внедрить регулярные встречи один на один (1:1), чтобы вовремя заметить признаки выгорания: цинизм, раздражительность, снижение продуктивности. Если сотрудник «погас», предложите ему взять несколько дней отпуска или обратиться к психологу. Многие современные компании включают психологическую помощь в пакет ДМС, и это один из самых эффективных инструментов удержания талантов.
Как создать культуру «безопасного» восстановления
Команда, которая боится ошибиться, работает медленно и стрессует больше. Чтобы этого избежать, внедряйте культуру blameless post-mortems (разборов без поиска виновных). Когда фокус смещается с «кто виноват» на «почему система позволила этому случиться», люди перестают скрывать свои ошибки и начинают помогать друг другу.
Публичная похвала тоже работает. Если команда героически восстановила сервис в выходные, это должно быть отмечено не просто словами «спасибо», а чем-то ощутимым: дополнительными выходными, премией или даже простым признанием в общем чате. Это перекрывает негативный опыт стресса позитивным подкреплением.
В конечном счете, продакшн-инцидент - это всего лишь работа. Ни один упавший сервер не стоит вашего здоровья. Помните, что умение вовремя сказать «нет» новой задаче, когда вы на грани истощения, и способность эскалировать проблему до того, как она станет катастрофой - это такие же профессиональные навыки, как знание языка программирования или умение настраивать CI/CD.
Что делать, если сотрудник впал в ступор во время аварии?
Необходимо немедленно снять с него ответственность за принятие решений. Переведите его в роль наблюдателя или поручите простую механическую задачу (например, записывать таймлайн событий). Стресс блокирует префронтальную кору головного мозга, и в таком состоянии человек физически не может мыслить логически. После инцидента обязательно проведите встречу 1:1, чтобы поддержать его и разобрать ситуацию без давления.
Как правильно писать Incident Report, чтобы он не превратился в обвинительный акт?
Фокусируйтесь на фактах и временных метках. Вместо фразы «Разработчик Иван забыл обновить конфиг» используйте «В 14:20 в конфигурационный файл была внесена ошибка из-за отсутствия автоматической валидации». Описывайте не действия людей, а недостатки процессов и инструментов, которые привели к сбою. Цель отчета - создать список задач (Action Items), которые предотвратят повторение ситуации.
Сколько людей должно быть в «боевой» группе во время инцидента?
Оптимальный размер группы - от 3 до 7 человек. Если людей больше, начинается «эффект толпы»: коммуникации перегружаются, люди начинают перебивать друг друга, а принятие решений замедляется. Если нужны эксперты из других отделов, подключайте их точечно для консультаций, но не оставляйте их в основном канале связи, чтобы не создавать лишнего шума.
Как понять, что команда находится на грани выгорания после серии аварий?
Следите за косвенными признаками: люди перестали шутить в чатах, стали чаще брать больничные, или, наоборот, работают сверхурочно без просьбы руководства (гиперкомпенсация). Если на обычные вопросы коллеги отвечают агрессивно или с иронией - это сигнал, что эмоциональный ресурс исчерпан. В таком случае необходим коллективный «разгрузочный» день или командное мероприятие, не связанное с работой.
Помогают ли tabletop-учения на самом деле?
Да, потому что они создают «мышечную память» мозга. Когда происходит реальный сбой, мозг не тратит энергию на вопрос «А что вообще происходит?», а переходит к этапу «Мы это уже обсуждали, я знаю, где лежат доступы и кому звонить». Это снижает уровень первичного стресса и позволяет команде действовать быстрее и спокойнее.